Кто победит на выборах в Мексике? Вот как закрываются избирательные участки
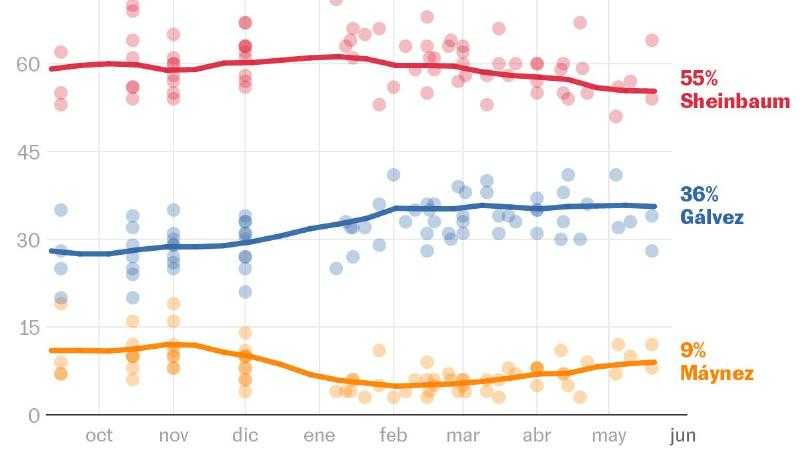
Победить его так же легко (или трудно), как наблюдать за промахом Стивена Карри или другого специалиста по штрафным броскам. В действительности мы описываем вероятность того, что опросы ошибутся (или сдвинутся) настолько, что Гальвес победит Шейнбаума. Другие прогнозисты с различными методиками сходятся во мнении, что Шейнбаум является твердым фаворитом в это воскресенье. Прогнозное сообщество Metaculus, имеющее один из лучших показателей исторической точности, считает, что вероятность победы Шейнбаума составляет 89 %. А на рынке прогнозов Polymarket ей дают 90 % шансов. Наконец, Expansión опубликовал результаты другой модели, основанной на опросах, которая повышает вероятность победы Шейнбаум до 98 %. Прогнозы сделаны с помощью статистической модели, основанной на опросах и их исторической точности. Она похожа на те, что мы использовали в Испании в 2023 году и дважды в 2019 году - в Андалусии, Каталонии и Мадриде. А также в Мексике шесть лет назад, во Франции и Великобритании. Модель работает в три этапа: 1) агрегирование и усреднение опросов, 2) учет ожидаемой неопределенности и 3) моделирование 20 000 выборов с расчетом вероятностей. Шаг 1. Усреднение опросов. Для повышения точности усреднения мы учитываем десятки опросов. В основном данные были собраны сайтом Oraculus.mx. Среднее значение взвешивается, чтобы придать разный вес каждому опросу в зависимости от двух факторов: организатора опроса (фирмы без послужного списка имеют меньший вес; исключаются те, кто не публикует свои данные в INE) и даты. Мы хотим придать больший вес недавним опросам при расчете среднего значения, и чтобы в последний день имели значение только последние опросы, опубликованные каждым опросчиком. Для этого мы присваиваем веса опросам по экспоненциально убывающему закону. Мы также определяем полосу исключения, в которой игнорируются опросы старше 30 дней. Кроме того, мы наказываем повторные опросы от одного и того же опроса. При вычислении среднего значения по дате ближайший опрос каждого дома имеет вес один, но остальные их опросы практически игнорируются. Средние показатели, подобные нашим, можно рассматривать как консенсусную оценку. Вместо того чтобы полагаться на одного опросчика, они объединяют суждения и предположения многих. Средние показатели снижают уровень шума, не позволяя тенденциям скакать вверх-вниз по воле случая. И самое главное: доказано, что они повышают точность. Шаг 2. Учет неопределенности опроса. Это самый сложный и самый важный шаг. Нам нужно оценить ожидаемую точность опросов в Мексике. Насколько велики обычные ошибки? Насколько вероятны ошибки в 3, 5 или 15 пунктов? Чтобы ответить на эти вопросы, изучаются десятки опросов в Мексике и тысячи опросов за рубежом. Калибровка ожидаемых ошибок. Сначала я оценил погрешность опросов в Мексике. Я создал базу данных с опросами по семи выборам с 2000 года. Средняя абсолютная ошибка (MAE) средних опросов в Мексике по кандидатам или партиям, учитывая тех, кто набрал более 10 % голосов, составила около 3,8 пункта на президентских выборах и 2,2 пункта на выборах в законодательные органы. Иными словами, отклонения в четыре-пять пунктов были обычным явлением, а погрешность (95 %) составляла около девяти пунктов. Поскольку семь выборов - слишком мало, чтобы делать серьезные выводы, мы также проанализировали около двадцати голосований в других странах Латинской Америки, где ошибка MAE составила 4,1 пункта. В итоге, следуя принципу предосторожности, я решил, что наша модель предполагает MAE в 3,8 пункта в Мексике. Более того, эта неопределенность модулируется с учетом двух дополнительных факторов: размера партии-кандидата (потому что легче оценить голоса партии, если они составляют около 5 %, чем если они близки к 50 %) и близости выборов (потому что опросы в конце срока почти всегда более точны). Для подгонки этой части модели я использовал базу данных Дженнингса и Влезиена, опубликованную в Nature, и проанализировал ошибки 4 100 опросов на 241 выборах в 19 западных странах. Выбор типа распределения. Чтобы учесть неопределенность в голосовании за каждого кандидата от партии в каждой симуляции, я использую многомерное распределение. Я использую t-распределение вместо нормального распределения, чтобы у него были более длинные хвосты (эксцесс): это повышает вероятность возникновения экстремальных событий. Преимущества такого предположения объяснил Нейт Сильвер. Я оцениваю уровень эксцесса с помощью вышеуказанной базы данных. Затем я определяю ковариационную матрицу этих распределений так, чтобы сумма голосов не превышала 100 % (идея Криса Ханретти). Наконец, я масштабирую ширину ковариационных матриц так, чтобы полученные распределения голосов имели ожидаемые MAE и стандартное отклонение в соответствии с калибровкой. Шаг 3. Моделирование. Последний шаг состоит в запуске модели 20 000 раз. Каждая итерация представляет собой симуляцию выборов с процентами голосов, изменяющимися в соответствии с распределением, определенным на предыдущем шаге. Результаты этих симуляций позволяют рассчитать вероятности того, что каждый кандидат наберет наибольшее количество голосов и станет президентом. Почему именно опросы. Эта модель полностью основана на опросах. Бытует мнение, что опросы ненадежны, но на самом деле они работают. Опросы редко бывают идеальными, но нет альтернативы, которая была бы доказана как лучшая. Подпишитесь на рассылку EL PAÍS Mexico и избирательный канал WhatsApp и получайте всю самую важную информацию о текущих событиях в этой стране.